A guide to “Separate Chaining” and its implementation in C
Hashing has the fundamental problem of collision, two or more keys could have same hashes leading to the collision. Separate Chaining or Open Hashing is one of the approaches to eliminate collision. The idea is to use linked list for all the keys with the same hashes.
Follow this link to learn more about the Hashing and its collision resolution strategies.
Load Factor:
This is very important to understand before getting deeper into any collision resolution technique. Load Factor denoted by “α” is the measurement of how well the elements in the Hash Table are distributed. It is defined as,
No. Of stored elements in the table
Load Factor (α) = __________________________________________ = n/m
Capacity(or size) of Table at the momentFrom this onwards, all the below explanations are taking consideration of Separate Chaining only.
Say n = 10 elements and m = 2, then, α = 5. It says on an average max number of elements per slot is five or length of chain per slot is five.
Note:- Don’t confuse with the load factor being mentioned in some places as less than 1 (and greater than 0), that one is w.r.t. open addressing/close hashing.
In practice, the load factor is taken as constant(5, 10, 20..) for Separate Chaining. It can be clearly seen for searching operation, a complete chain to a slot has to be visited in worst and that would be α. Hence, the time complexity of look up operation will be constant O(1) provided Hash function should be distributing elements uniformly.
What if the average number of elements in the chain(also referred as block) exceeds this load factor, then, the size of the table is increased call it rehash. See the reHash() function in the implementation,
Implementation:
Hashing could be implemented in two ways:
1. Static Hashing
When the data are fixed means set of fixed number of keys. Declare an array of fixed size for the table size as per the requirement.
2. Dynamic Hashing
When the data are not fixed means the set of keys change dynamically. See the following implementation,
First, decide the load factor, let’s take it as five LOAD_FACTOR = 5.
For the sake of simplicity, Hash function will be Data mod(Table capacity). Hash function returns the index where elements will be stored, also called as key.
Say maximum elements we require to store is Ten, then given the number of elements and LOAD_FACTOR we can calculate the Capacity or the size of the hash table as
Capacity of Hash Table(m) = LOAD_FACTOR * No. Of Elements(n)
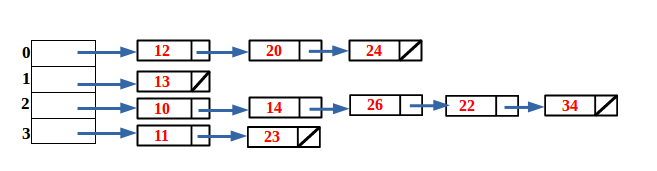
For each element insertion, we’ll verify if LOAD_FACTOR get increased which means the number of capacity should be increased i.e. reHash(). See the following pictures,

#include<stdio.h>
#include<stdlib.h>
#define LOAD_FACTOR 5
typedef struct listNode{
int key;
int data;
struct listNode *next;
}ListNode;
typedef struct hashTableNode{
int bCount; // count of elements in a block or chain
ListNode *next;
}HashTableNode;
typedef struct hashTable{
int countOfElement; //count of elements in the hash table
int tCapacity; // table capacity/size/slots
HashTableNode *table;
}HashTable;
HashTable *h = NULL;
int hashFun(int data, int tCapacity){
return data % tCapacity;
}
void createHashTable(int noOfEelement){
h = (HashTable*)malloc(sizeof(HashTable));
h->countOfElement = 0;
h->tCapacity = noOfEelement/LOAD_FACTOR;
h->table = (HashTableNode *)malloc(h->tCapacity * sizeof(HashTableNode));
for(int i = 0; i<h->tCapacity; i++){
h->table[i].next = NULL;
h->table[i].bCount = 0;
}
}
ListNode *createNode(int data){
ListNode *temp;
temp = (ListNode *)malloc(sizeof(ListNode));
int index = hashFun(data, h->tCapacity);
temp->key = index;
temp->data = data;
temp->next = NULL;
return temp;
}
int searchToHashTable(int data){
int index = hashFun(data, h->tCapacity);
ListNode *temp = h->table[index].next;
while(temp){
if(temp->data == data)
return 1;
temp = temp->next;
}
return 0;
}
void reHash(){
HashTableNode *oldTable;
int oldCapacity = h->tCapacity;
oldTable = h->table; h->tCapacity = h->tCapacity*2;
h->table = (HashTableNode *)malloc(sizeof(HashTableNode) * h->tCapacity);
if(!h->table){
printf("Allocation Failed");
return;
}
for(int i = 0; i<h->tCapacity; i++){
h->table[i].next = NULL;
h->table[i].bCount = 0;
}
for(int i = 0; i<oldCapacity; i++){
ListNode *temp = oldTable[i].next, *temp2;
while(temp){
int index = hashFun(temp->data, h->tCapacity);
temp2 = temp; temp = temp->next;
if(h->table[index].bCount){
temp2->next = h->table[index].next;
h->table[index].next = temp2;
h->table[index].bCount++;
}
else{
h->table[index].next = temp2; temp2->next = NULL;
h->table[index].bCount++;
}
}
}
}
int insertToHashTable(ListNode *newNode){
int index = newNode->key;
int data = newNode->data;
if(searchToHashTable(data))
return -1;
newNode->next = h->table[index].next;
h->table[index].next = newNode;
h->table[index].bCount++;
h->countOfElement++;
if(h->countOfElement > h->tCapacity * LOAD_FACTOR)
reHash();
return 1;
}
int deleteToHashTable(int data){
int index = hashFun(data, h->tCapacity);
ListNode *temp = h->table[index].next, *prev = NULL;
while(temp){
if(temp->data == data){
if(prev != NULL){
prev->next = temp->next;
} else{
h->table[index].next = temp->next;
}
free(temp);
h->table[index].bCount--;
h->countOfElement--;
return 1;
}
prev = temp; temp = temp->next;
}
return 0;
}
int main(void){
createHashTable(10);
insertToHashTable(createNode(10));
insertToHashTable(createNode(11));
insertToHashTable(createNode(12));
insertToHashTable(createNode(13));
insertToHashTable(createNode(14));
insertToHashTable(createNode(20));
/*searching element 21 when it's not in the table*/
if(searchToHashTable(21))
printf("Found");
else
printf("Not found");
insertToHashTable(createNode(21));
/*searching element 21 when it's in the table*/
if(searchToHashTable(21))
printf("\nFound");
else
printf("\nNot Found");
if(deleteToHashTable(21))
printf("\nElement 21 deleted");
/*searching element 21 when it's deleted from the table*/
if(searchToHashTable(21))
printf("\nFound");
else
printf("\nNot Found");
insertToHashTable(createNode(26));
insertToHashTable(createNode(22));
insertToHashTable(createNode(23));
insertToHashTable(createNode(24));
printf("\n\n****Hash Table before capacity get doubled****");
printf("\nTable Capacity = %d, Total elements = %d\n", h->tCapacity, h->countOfElement);
for(int i = 0; i< h->tCapacity; i++){
printf("[%d]", i);
for(ListNode *temp = h->table[i].next; temp; temp=temp->next){
if(temp->next)
printf("%d->", temp->data);
else
printf("%d", temp->data);
}
printf("\n");
}
/*after the execution of below line number of elements become 11
* LOAD_FACTOR = 11/TableCapacity = 11/5 = 5.2
* 5.2 > actual LOAD_FACTOR decided. Thus, Capacity of Table has to be doubled*/
insertToHashTable(createNode(34));
printf("\n****Hash Table after capacity get doubled****");
printf("\nTable Capacity = %d, Total elements = %d\n", h->tCapacity, h->countOfElement);
for(int i = 0; i < h->tCapacity; i++){
printf("[%d]", i);
for(ListNode *temp = h->table[i].next; temp; temp = temp->next){
if(temp->next)
printf("%d->", temp->data);
else
printf("%d", temp->data);
}
printf("\n");
}
return 0;
}
Output:-
Not found
Found
Element 21 deleted
Not Found
****Hash Table before capacity get doubled****
Table Capacity = 2, Total elements = 10
[0]24->22->26->20->14->12->10
[1]23->13->11
****Hash Table after capacity get doubled****
Table Capacity = 4, Total elements = 11
[0]12->20->24
[1]13
[2]10->14->26->22->34
[3]11->23
Advantage and disadvantage of Separate Chaining:
- Easier to implement
- Look up time can be O(n) in worst case.
- Consumes high memory
Applications:
Separate Chaining is mostly used in cryptography.
Knowledge is most useful when liberated and shared. Share this to motivate us to keep writing such online tutorials for free and do comment if anything is missing or wrong or you need any kind of help.
Keep Learning… Happy Learning.. 🙂
thanks for your awesome tutorial about hash table.